
Ein generatives Text-zu-Bild-Maschinenlernmodell lokal zu betreiben hat viele Vorteile: ein hohes Maß an Konfigurierbarkeit, der Einsatz eigener oder fertiger Modelle, eigene LoRa-Modelle, keine Kosten (außer Energie) oder aber schlicht einen unzensierten Zugang zu dieser Technologie. In den folgenden Absätzen zeige ich, wie mit einer Stable Diffusion mit einer grafischen Oberfläche auf dem eigenen Rechner genutzt werden kann.
Stable Diffusion dient der Generierung von Bildern aus Textbeschreibungen. Es verwendet Techniken der Bildverarbeitung und des maschinellen Lernens, um auf Basis eines gegebenen Textes realistische oder kreative Bilder zu erstellen. Das Modell funktioniert, indem es ein Bild schrittweise von einem anfänglichen verrauschten Zustand aus diffundiert, bis es das endgültige Bild erzeugt, das den Textvorgaben entspricht.
SDGUI – eine grafische Oberfläche für Stable Diffusion
Benötigte Software
SDGUI ist eine Oberfläche, welche die Benutzung von Stable Diffusion im Browser ermöglicht. Weiters ist noch ein Modell nötig, damit Stable Diffusion visuelle Inhalte generieren kann. Mit den folgenden Links können die nötigen Softwarekomponenten heruntergeladen werden. Eine Installationsanleitung und Nutzungshinweise sind im SDGUI-Github-Link enthalten.
- SDGUI: https://github.com/FahimF/sd-gui
- Download eines Modells, zB. bei Huggingface: https://huggingface.co/
- Hugingface Stable Diffusion Modellseite: https://huggingface.co/CompVis/stable-diffusion-v1-4
Voraussetzungen für SDGUI
- Python installiert
- Eine Stable Diffusion-Installation
- Idealerweise eine Grafikkarte mit CUDA-Kernen (NVIDIA)
Noch einfacher – NMKD
Der wahrscheinlich einfachste Weg zu einer funktionierenden Installation ist über das NMKD-Projekt. Es ist nicht ganz aktuell, aber ein guter Einstieg in die Materie. Folgende Voraussetzungen sollten dafür erfüllt sein:
- Betriebssystem: Windows 10/11 64-bit
Minimum:
- GPU: Nvidia GPU with 4 GB VRAM, Maxwell Architektur (2014) oder neuer
- RAM: 8 GB RAM (Achtung: Das Windows Pagefile sollte aktiviert sein bei nur 8 GB). Die Windows-Auslagerungsdatei (Pagefile) ist eine Datei, die von Windows erstellt und verwaltet wird, um die Speichernutzung zu verwalten. Sie ist eine virtuelle Auslagerungsdatei, die als Zwischenspeicher zwischen dem physikalischen Arbeitsspeicher (RAM) und der Festplatte dient.
- Laufwerk: 10 GB + 5 GB temporären Speicherplatz
Empfohlen:
- GPU: Nvidia GPU mit 8 GB VRAM, Pascal Architektur (2016) oder neuer
- RAM: 16 GB RAM
- Disk: 12 GB auf einer SSD + GB temporären Speicherplatz
Benötigte Software
NMKD: https://nmkd.itch.io/t2i-gui
Ein Modell für Anfänger ist bei einem der verfügbaren Downloads bereits enthalten. Einfach bei den möglichen Downloads SD GUI 1.11.0 (Including SD 1.5 model) wählen.
Es werden noch weitere Modelle bzw. LoRA-Modelle von Huggingface oder ähnlichen Quellen wie civit.ai benötigt, wenn man ein wenig experimentieren möchte. Es sollte darauf geachtet werden, dass die Modelle mit Stable Diffusion 1.5 kompatibel sind und aus Sicherheitsgründen im .safetensors-Format vorliegen! Safetensors verhindert das Ausführen von Schadcode, ist schnell und ein serialisiertes Format.
Die unterschiedlichen Formate können auch direkt in NMKD konvertiert werden unter Developer Tools/Convert Models (viertes Icon von rechts in der obersten Leiste). Dort kann auch eine Command Line aufgerufen oder Modelle gemerged werden.
Mit einem Model-Merge können mehrere Modelle anhand von Gewichtungen kombiniert werden, um diese zu vereinen. So kann beispielsweise ein Modell für fotorealistische Gesichter mit einem Anime-Modell kombiniert werden. Das Ergebnis ist eine gewichtete Mischung, wo Eigenschaften beider Modelle in die Generierung einfließen.

Die Modelle
Grundsätzlich kann man 4 Modelle unterscheiden, die von Stable Diffusion genutzt werden können.
- Checkpoint models: Typisch für die Nutzung mit Stable Diffusion. Sie beinhalten die Datenbasis für die Bildgenerierung.
- Textual inversions (embeddings): Kleine Dateien, die neue Schlüsselwörter zur Generierung neuer Objekte oder Stile hinzufügen. Diese werden immer in Kombination mit einem Checkpoint-Model genutzt.
- LoRA models: LoRA (Low-Rank Adaptation) ist eine Trainingstechnik zum Feintuning von Stable Diffusion Modellen. LoRA bietet einen guten Kompromiss zwischen Dateigröße und Trainingsleistung.
- Hypernetworks: Ähnlich wie LoRA kann mit Hypernetworks, die als neuronale Netze vorliegen, der Stil eines Checkpoint Modells verändert werden. Im Allgemeinen werden aber mit LoRA Modellen bessere Ergebnisse erzielt.
LoRA Training
Checkpoint Modelle können, wie bereits oben erwähnt, mit LoRA Modellen optimiert werden. Diese können auf huggingface bzw. civit.ai heruntergeladen oder selbst erstellt werden. Dazu kann über Train LoRA Models (das fünfte Icon von rechts in der oberen Leiste) dieser Prozess gestartet werden. Anhand von bereitgestelltem Bildmaterial und den Beschreibungen (wichtig für die Keywords bzw. Triggerwords), wird das Modell trainiert. Das ist deutlich weniger aufwändig als ein komplettes Checkpoint Modell zu trainieren (auf dieses Thema gehe ich im vorliegenden Beitrag nicht ein).

Ist ein LoRA-Modell trainiert oder aus externen Quellen im Ordner Models/LoRAs eingebunden, kann die Bildgenerierung mit den Triggerwords im Prompt gestartet werden. Das folgende Beispiel zeigt die Auswirkung eines Line-Art-LoRAs.


Promptcrafting
Die Formulierung von Prompts ist entscheidend, da Punkte, Kommas und andere Satzzeichen die Interpretation beeinflussen können. Eine präzise und klare Eingabe ist wichtig, damit diese mit den Trainingsdaten übereinstimmt.
Ein guter Prompt besteht aus folgenden Angaben.
- Subjekt: Worum es geht, was man sehen will.
- Medium: Oil, Photography, Painting,…
- Stil: Fantasy, Cyberpunk, Dark Art,…
- Genauigkeit: Detailed, in focus, out of focus,…
- Zusätzliche Details
- Farbe: Silver, bright gold,…
- Ausleuchtung: studio light, butterfly light,…

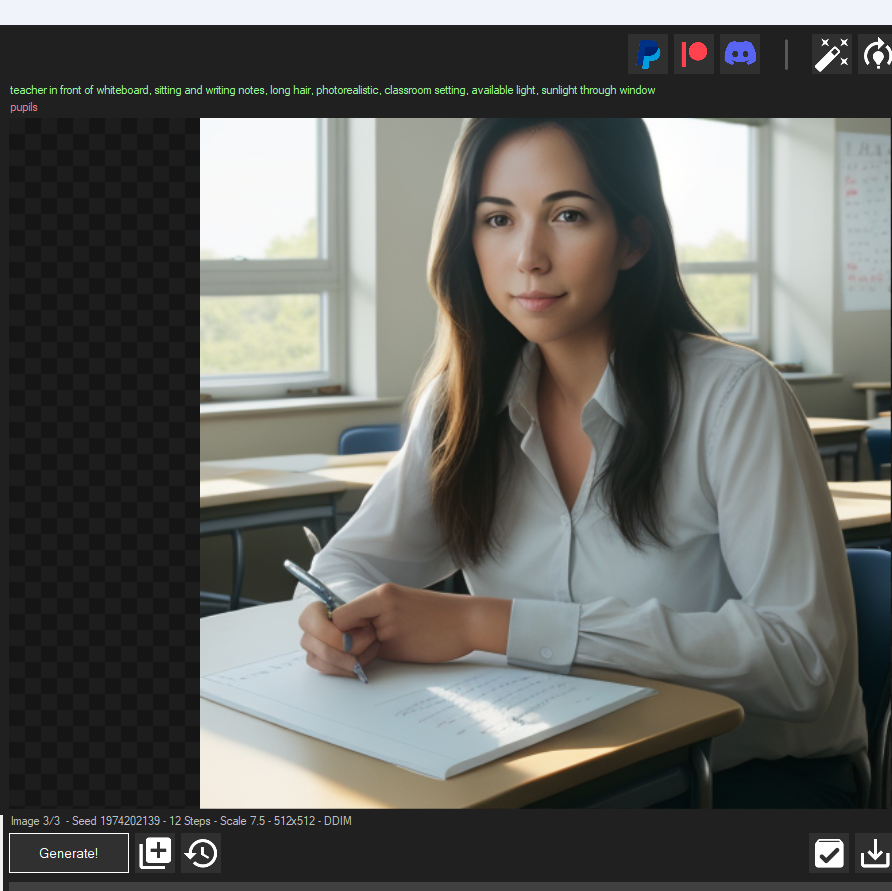
Wichtige Parameter und Einstellungen
- Negative Prompts: Was nicht generiert werden soll. Dies kann helfen, unerwünschte Elemente aus dem Bild fernzuhalten.
- Generation Steps: Die Sampling-Schritte legen fest, wie viel Rechenaufwand in die Erstellung des Bildes gesteckt wird und welche Qualität das Endergebnis hat. Mehr Schritte bedeuten in der Regel eine höhere Qualität, aber auch eine längere Rechenzeit.
- Sampler: Die Unterschiede zwischen den meisten Sampling-Methoden sind oft nicht sehr groß.
- Seed: Der Seed-Wert bestimmt die Zufallskomponente der Bildgenerierung. Wenn der gleiche Seed bei identischen Einstellungen verwendet wird, entsteht immer das gleiche Bild. Dies ist nützlich, um reproduzierbare Ergebnisse zu erzielen.
- CFG Scale: Der CFG-Scale (Classifier-Free Guidance Scale) beeinflusst die Bildqualität erheblich. Ein niedrigerer Wert kann oft zu einem besseren Bild führen als ein höherer, da er die Balance zwischen Originalität und dem, was der Prompt beschreibt, reguliert.
- Auflösung: Die Bildauflösung kann in den Feldern „Width“ (Breite) und „Height“ (Höhe) eingestellt werden. Welche Auflösung möglich ist, hängt von deiner Hardware und den eingestellten Parametern ab.
- Base Image: Bild laden, das durch Prompt angepasst wird. Dadurch wird img2img, inpaint, outpaint usw. erst möglich.
- Img2Img: Das Ausgangsbild variieren, siehe Beispiel unten. Besonders wichtig ist hier die Einstellung „Image Strength“, die bestimmt, wie stark das Originalbild mit dem neuen Bild vermischt wird. Ein niedriger Wert erhält mehr vom Originalbild, während ein hoher Wert das neu generierte Bild stärker hervorhebt.
- Masken: Masken/Alpha Kanal sind nützlich, um nur bestimmte Bereiche des Bildes zu bearbeiten.
- Outpainting: Bild über den vorhandenen Bereich hinaus vergrößern. Achtung: Das Bild muss transparente Bereiche enthalten, die ergänzt werden oder die Resolution größer als der Input sein.
- Inpainting: Fehlende oder unerwünschte Bereiche im Bild ergänzen. Idealerweise werden diese zuvor mit einer Maske (Alpha Kanal) im Bild maskiert.
- Symmetry Settings: Perfekt, um Texturen für die 3D-Modellierung zu erstellen.


